

If you come here often you might have noticed some changes.
On desktop everything is smaller… On mobile it’s easier to navigate… Images are higher quality…
Everything is faster. Happier. More productive.
This is the result of two months laboring in the code mines to move my website from Gatsby to Astro.
There aren’t really many (or any?) other Gatsby/Astro sites with hundreds of gigabytes of images and audio like mine, so I encountered some interesting problems during the migration.
I’m going to summarize how that process went, as well as thoughts that occurred to me along the way. Hopefully my experiences will be useful if you’re in a similar position, or if you’re just curious about how this sort of site comes to be.
Why leave gatsby?
If you’ve spent any amount of time in web dev you’ll know about the churn: The tech everyone loves one month is hated the next month, and not necessarily because of anything inherent to the tech. As they say in web dev, one day you’re in, and the next day you’re out.
My old site was written for Gatsby. I chose Gatsby because at the time it was the static site generator everyone liked. And I liked it too, the GraphQL stuff was useful for a site as data-driven as mine, almost like having a real database but only in the build process.
I also had high hopes for the image processing and rendering system, a major feature of Gatsby. My site has over 20,000 photos, and I wanted to process and serve these at optimal resolutions for all devices, to help speed up the user experience, and also save hosting costs.
Before Gatsby, I was using custom scripts to process images separately from the site. At the time this felt clumsy. Gatsby in contrast would handle everything without any fuss, I would be able to just say “give me all the images associated with this gig” and I’d get nice responsive image components. That was the dream anyway.
(Incidentally I wrote about the transition to Gatsby back in 2019, which is interesting reading in retrospect)
But then, over time, two things happened.
First it became clear my site (with over 20,000 images, many 100mb+ MP3 files, and over 1,000 pages) was too much for Gatsby, at least in the way they intended it to be used. Over the years, my build times became longer and longer, reaching multiple hours. Thanks to Gatsby being open source, I was able to identify why this was and contribute a fix, which was then rolled into version 5.5 and drastically sped up my build times.
(This was basically the ideal open source experience actually. Identifying a problem, working with the maintainers to fix it, then having it rolled into a release, all within a few weeks. It really endeared me to Gatsby, and is one of the reasons why I stuck with it despite the issues I encountered. Even though my site was clearly an outlier (most Gatsby sites don’t have thousands of photos) the maintainers still identified my fix as useful and chose to merge it in.)
But as of earlier this year my build time was back to four hours or more. Which was pretty annoying and really hurt my dev workflow.
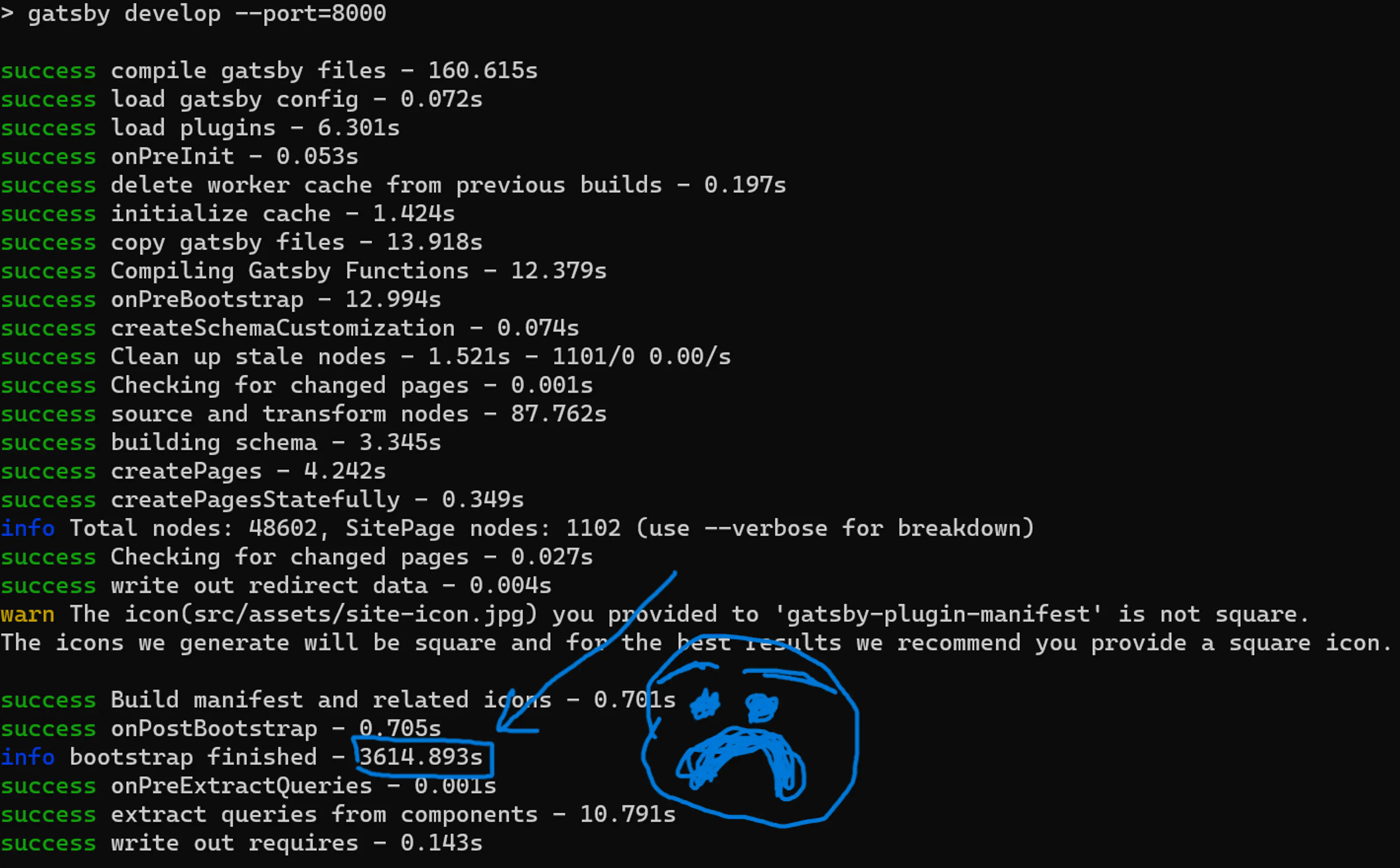
The second, and biggest impetus for the switch, was Gatsby being sold to some trash SAAS company, who then fired everyone and made it clear they’re not interested in collaborating with the open source community anymore. So I’m out. Gatsby is dead.
And the thing driving all of this, the reason why I put work into the website, is that I believe the true value of what I have isn’t the media, it’s the ability to browse and discover it. So this website is really the most important thing I do.
What to use instead
It looked like the current Thing is Astro. Astro seemed suitable for my purposes, it seemed less opinionated and lighter than Gatsby, which would be good since I could theoretically adapt it to my use case more effectively.
The big selling point with Astro is that it’s framework agnostic, so if one day React goes out of favor you can switch to Vue or whatever without moving to another platform. I like this.
There’s an emphasis on shipping as little JavaScript to the browser as possible, which appeals to me less… On a site this image-heavy worrying about a few hundred kilobytes of JavaScript feels silly. But I admire the goal of relentlessly optimizing performance.
Since I was going to be making substantial changes anyway, there was a bunch of other stuff I wanted to do. Even though Astro can do image processing like Gatsby, I wanted to go back to processing large files separately due to aforementioned issues. I also wanted to move to TypeScript, make schema improvements, and shed technical debt.
The migration process
Astro has documentation on migrating Gatsby to Astro to help all the people who, like me, are embarking on that journey. Initially I followed this documentation, but it soon became clear that the process was a lot less simple than the docs suggested, and I ended up basically just rewriting everything.
I approached it methodically, focusing on one section of the site at a time, and making reusable components as I went.
The loose overall process for migrating content (ie. a gig, an artist, a venue) was:
- Define a content collection (eg. Gigs)
- Define a layout for that collections entries (eg. Gig.astro)
- Define page templates to dynamically generate pages with that layout ( eg. […slug].astro)
And then components. This was where the bulk of the work was. The docs tell you to basically just rename it to astro, but it’s an entirely new paradigm compared to Gatsby’s React components, so it requires a bit more thought.
- Decide whether the component should stay as React, or can be ported as an Astro component
- If ported to Astro, define a Web Component to encapsulate any clientside behavior, and/or move props and non-clientside work into frontmatter
- Otherwise copy it as a React component, and tear out all the Gatsby specific stuff (eg. <GatsbyImage/> components)
Of course I was also moving to TypeScript, so there was work involved in making sure things were typed properly. And I had to write scripts for converting existing content to match my schema changes.
All up it took about two months of working in evenings and when I had time to spare on weekends to get something I deemed production ready.
Porting React components to Astro
An Astro component is basically one file which bundles the vanilla HTML, JavaScript (or TypeScript), and CSS for that component, as well as frontmatter which runs at build time.
Alongside those you can have framework components, React in my case but it works with just about anything. You have to explicitly tell Astro to load the framework if you want these components to be interactive. (You can also have framework components that are just rendered on the server and don’t have any interactive clientside behavior)
So to get the most out of astro, you need to think about which parts of the page need to be interactive and which don’t. Which is an interesting approach, and takes a while to get used to. Initially it was scary and different to me, so I was porting over React components as is. But then I read up on the Web Components API and realized a lot of the time I didn’t really need React.
In fact contrary to everything I thought I knew, a lot of the time React was making things harder, not easier.
An example of this was my Artists page component, which basically just wrapped a vanilla JS library (ShuffleJS) in React via useRef hooks. I replaced this with a web component which wraps that same library but in a tidier way without all the React cruft.
Similarly, the maps component used on the Venue page was just a React MapboxGL component, so tearing out React made a lot of sense there.
Coming from 53 React components on Gatsby, I ended up with 39 Astro components and just 6 React components. The only components I chose to keep on React were ones which required a higher level of interactivity, but honestly I could probably move those to Web Components fairly easily too.
Web Components API on its own is neat, but Astro provides a really nice framework around it. It feels like a natural fit for architecting an application with web components.
Making collections
Instead of defining a GraphQL schema like in Gatsby (or allowing it to be inferred), we have this concept of “content collections” in Astro. These can automatically generate types for typescript (very nice), and allow you to generate a page dynamically from a slug for each “entry” in the collection.
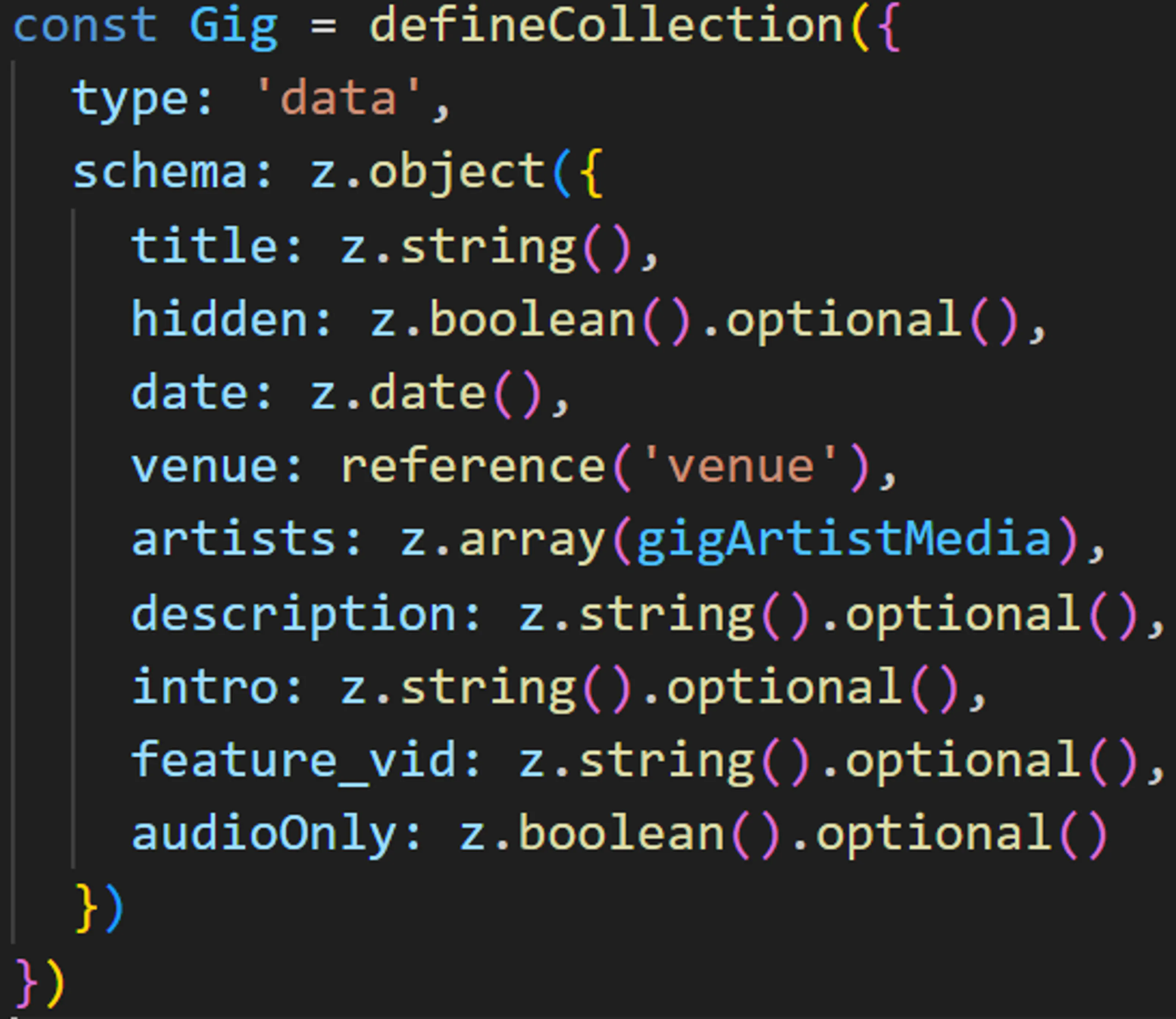
Out of the box they’re fairly simple, only offering access to frontmatter fields, which probably works for most users. But, in classic Astro style, you can roll your own methods for doing just about anything to these guys.
For my purposes I defined an interface for adding “extra” fields to the built in collection entries, and then made a loadAndFormatCollection method which I would use instead of the built in getCollection method, to return collection entries with my computed fields attached.
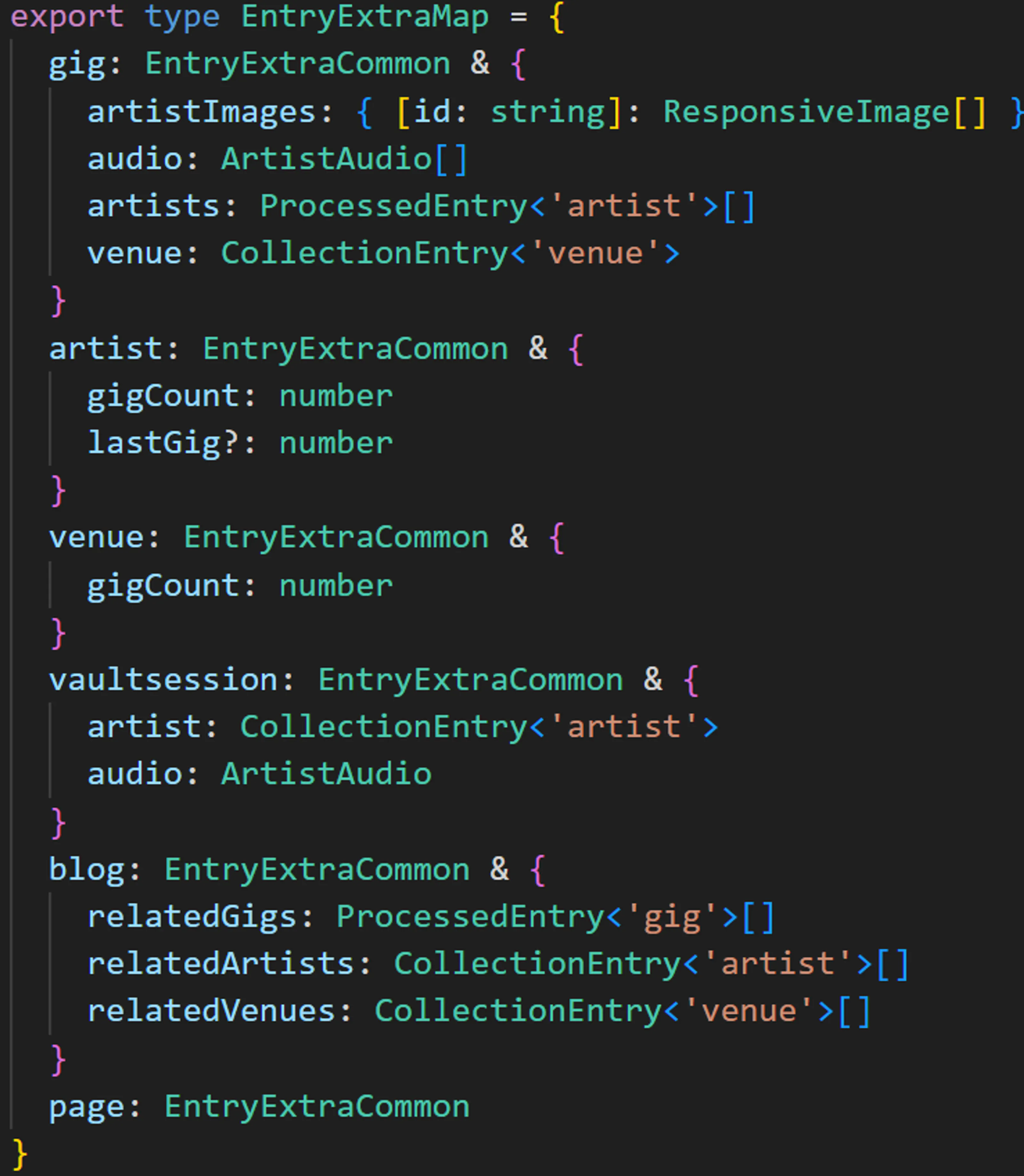
For example, all entries would get an absolutePath, and a cover image. Gig entries would have their related entities (Artists and Venues) queried and attached, to save having to query this information multiple times in multiple places. And this also made it possible to bypass Astro’s built in image system and use my own.
I initially felt like Astro should have a built-in mechanism for adding fields to entries (like Gatsby does in gatsby-node.js), but why write a system for something which is already possible?
Moving my Styled Components to Vanilla Extract
I was using styled components in Gatsby, and styled components aren’t really compatible with the way Astro does things, so I had to pick a new approach.
Astro encourages you to just put styles in style tags, which it then processes underneath via postCSS to scope them and whatever else, but there were a few issues with this from my perspective.
The major one was that passing variables into these style tags made the style inline. I have components which set dynamic styles based on props, and I don’t want all these styles to be inline.
Also I needed a solution for my React components anyway.
So I went with Vanilla Extract instead. I enjoyed the API, it let me write dynamic styles in TypeScript which are then compiled down to CSS for the browser (however later Vanilla Extract started causing me problems, so I’m not sure if this was the right decision).
I also ripped out Rhythm and Scale, which I thought was a cool idea but it’s dead with Gatsby. I just set base sizes with variables and use CSS calc instead. I kept Polished though, I think it’s neat. And instead of Emotion’s global theme provider, I used Vanilla Extract’s theme provider which basically just sets CSS variables.
The result means all my CSS is now actually CSS, and not CSS in JS as with styled components, which should result in a performance improvement.
Getting the new custom media queries working was a bit of a pain… They don’t work if you put them in an Astro global style (perplexingly, something to do with load order I think), but I was able to use the PostCSS Global Data plugin and put them in their own file.
Something interesting I noticed is that the cascading aspect of cascading style sheets seems to have fallen out of favor. Everyone wants to write scoped styles now, so Astro’s style tags can’t be used to style child components, and Vanilla Extract makes you explicitly use a different function for writing styles that aren’t scoped. I get why this is, but in some cases it made things a bit more cumbersome than I thought it should… But as I got used to it, it became natural and probably prevented some bad practices.
Handling large images and audio files
The lesson I learnt from Gatsby is that static site generators are not intended to handle this many large files. Build directories are meant to be ephemeral and deletable without a big hassle, and having to re-generate tens of thousands of images is a big hassle. Also build systems sometimes like to hash files to determine if they’ve changed, and if you have 100mb+ MP3s this can be very slow.
So I decided it would be better to run a secondary task to process all my images, and put the processed versions in the public directory which Astro just copies as is. This feels like added complexity because there are more parts to maintain, but I think paradoxically it’s actually less complex.
Confusing simplicity and minimalism is a common human foible. We see it in modern car design where, for aesthetic minimalism, all buttons and knobs are removed in favor of one central screen.
But, contrary to what your brain might think on first impression, navigating through three layers of menu to adjust the temperature is less simple than sliding a slider, even if having multiple sliders for the temperature seems more complex.
Similarly, running one command to build your site and relying entirely on third-party dependencies to know how to do it might seem more simple, but because you’re essentially dealing with multiple nested blackboxes, like me you might run into problems which will add complexity.
Without GraphQL I had to find a way to dynamically grab files related to each content entity. Astro has a built in Astro.glob() function, but it doesn’t support dynamic paths, which I need so I can glob for files related to an entity ID. But since it’s just JavaScript, I had access to any number of NPM globbing libraries. I went with fdir since it claimed to be the fastest.
Then it was just a matter of coming up with a convention for storing media, and writing a script for processing it and moving it around.
The convention I settled on was filename/[contentdigest].[width].webp. Then I made a ResponsiveImage class which absorbs a directory of these images and parses them into srcsets and sizes to use with an image tag.
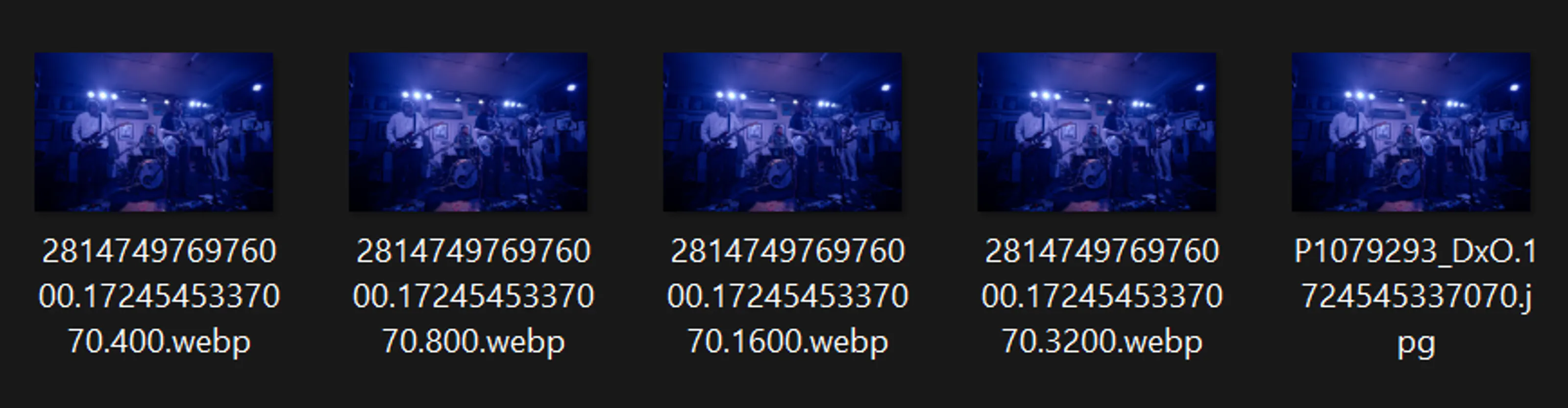
Then I just wrote a simple script which uses Sharp to generate WEBP proxies in various sizes and spits them out following my convention. It generates a content digest of each file which it can compare to input file metadata to know if it’s changed and needs to generate a new one (the same method I used for the fastHash option in Gatsby).
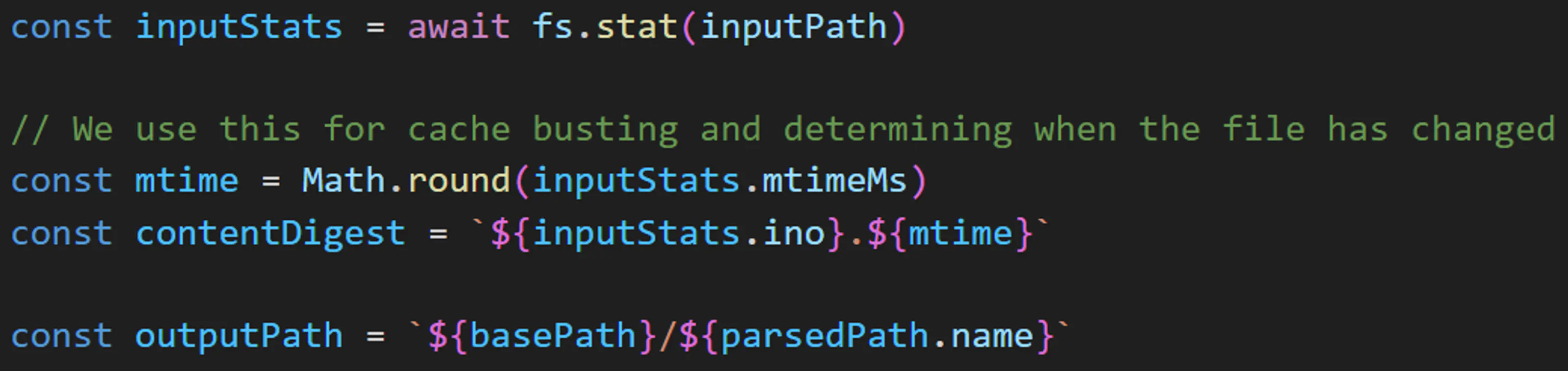
I tested this on a subset of media and found it to be very fast, much faster than Gatsby which tended to linger on “processing images” while it was doing something. Even on a mechanical disk it took minutes to check existing files for changes, and not much longer to generate proxies.
Once everything was tested, I did the big conversion from the old media to the new media. It needed to generate five aggregates for each of my photos, and was doing about one photo every two seconds, so it took a while.
While there’s undoubtedly more code to maintain, it feels good to know I have full control of this pipeline and can optimize it for my circumstances as opposed to Gatsby where I was at the whims of the open source community who wouldn’t necessarily cater to my niche usecase (understandably).
Redesign philosophy
Going in I didn’t intend to do a redesign, but since I was building everything from scratch I ended up rethinking a lot of stuff.
When I first designed the website, I was more motivated by what other sites did and what was “standard” web design. So I did the usual mobile first web UX where everything is big, and most effort is put into the mobile experience. This makes sense because mobile users are the majority. However, I’ve since realised there’s more to it than simply where the most users are.
Different types of users are in different contexts eg. sitting at a desk vs on the couch with a device which can easily go in and out of your pocket, and apps which are begging for your attention. So my theory is desktop users probably have more time, are more likely to be more focused, and so I should provide them with tools which fit that context, even if they’re a minority.
In a business you probably couldn’t do this. You would look at a feature used by a low percentage of users and say “why do we have this feature? nobody is using it”. Me on the other hand would say “wow those users must be epic, I better make that feature extra good for them”. I’m not driven by profit and bottom lines so I can afford to do that.
And this is the attitude the internet was founded on, before the rise of the monolithic platforms. It was just a bunch of weirdos in basements coding up stuff they thought other people might like. It wasn’t about appealing to anyone with fingers, it was about appealing to the people you wanted to appeal to.
So my goal was mobile first but desktop enhanced. Mobile functional, desktop flourishing. Moisturized. In its lane.
An example of this philosophy is the fixed side nav on desktop. Desktop monitors are wide, so it’s ok to sacrifice some horizontal real estate to a fixed navigation element if it makes users lives easier. And with so much content, ease of navigation is especially important. The point of the site isn’t just one gig/artist/venue, it’s the mise en scene. Then on mobile this navigation can just collapse down into a menu.
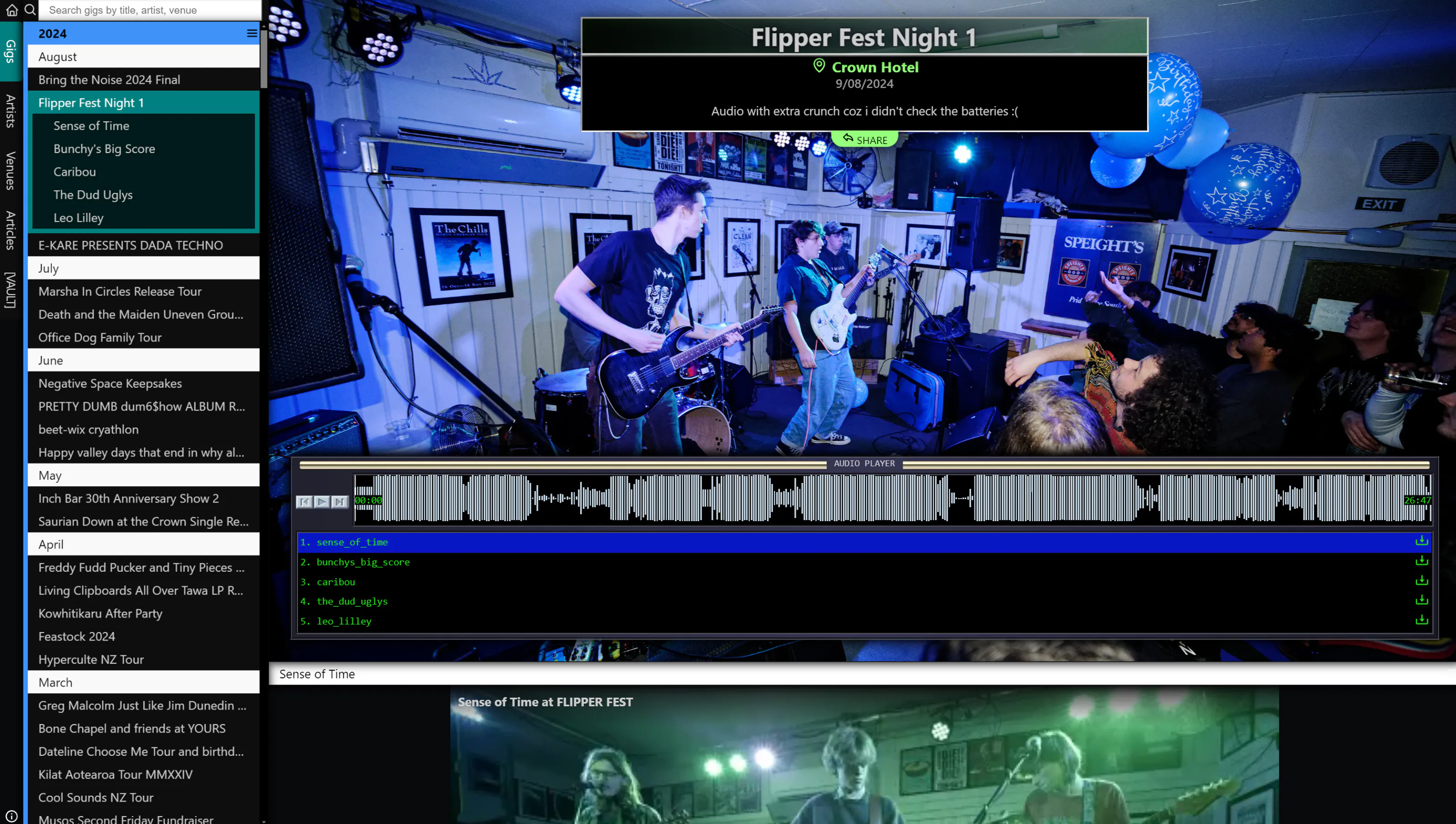
Also on desktop we don’t have to make click targets big enough for people’s fingers, so I made the UX elements smaller. A half-competent mouse user can usually click things pretty accurately, and smaller UX elements means more room for the rest of the layout.
More stuff on screen where there’s space should make it easier to navigate the library, but at the expense of visual impact, and at the risk of scaring people with visual clutter. But I don’t care about visual impact as much as usability. I prefer simplicity over minimalism.
The first build
I sort of expected this to be where errors show up due to the sheer size of it all, and I wasn’t wrong.
Vanilla extract woes
I first ran into errors with vanilla-extract (“The server is being restarted or closed. Request is outdated”).
Downgrading the Vite plugin to 3.9.5 seemed to fix it (second time I’ve had to downgrade it…) but then this broke a bunch of stuff in the style composition and I had to add some !importants. In general the Vanilla Extract Vite integration seems quite buggy, so bear that in mind.
File copying woes
Once I fixed the errors preventing build from happening, the build finished in 81 minutes, which is a lot longer than I expected. It seemed to be idle for much of the build too. So I went searching for answers.
It turned out that while Astro wasn’t processing my images, it was still copying them from the public directory into the dist directory, and they were still exposed to Vite which I think was doing some sort of file hashing.
Removing the large files from my public directory so neither Astro or Vite knew about them reduced the build down to 15 minutes. So it became clear that my original plan of storing my files in the public directory wasn’t going to work.
I ended up on a system where they’re in dist_media which is symlinked into the dist directory on deploy, so there’s only one copy of the files and neither Astro nor Vite need to care about them. I also had to remember to add this directory to the exclude list in all the configs to stop typescript and vite from looking at them or my dev server got very slow.
I also bought an SSD to see if that improved things (they’ve gotten so cheap) and formatted it with the new Windows 11 dev drive (it uses ReFS which supposedly improves performance for a bunch of devvy stuff).
(Update on dev drive: HUGE MISTAKE. One of my files got inexplicably corrupted, and Windows 11 dev drive uses a version of ReFS which isn’t supported by refsutils (the tool for salvaging corrupt files) and (bafflingly) there is NO version which supports it. Also there is no way for the corrupt file to be removed either. So basically I had to reformat to NTFS. Thanks Microsoft!)
The next breakthrough came when I optimized the globbing stuff in collection.ts by making it cache the results of all globs in memory.
By doing this I was able to get the entire build process down to under a minute. Which is a big improvement on 4 hours. You don’t really notice the benefits of being able to iterate and ship quickly until your build process takes 4 hours.

Deploying it
The docs for deploying to S3 are basically like “you want to deploy to s3? ok, use the AWS CLI” which is pretty funny, but I think it’s better than writing a complex integration which requires lots of maintenance and basically does what the CLI does except worse (aka Gatsby’s approach).
Since I’m just using the S3 CLI I can adjust the concurrency and consume more of my pipe… A data deploy with no new media is like 10 seconds, and a deploy with new images is much quicker than before.
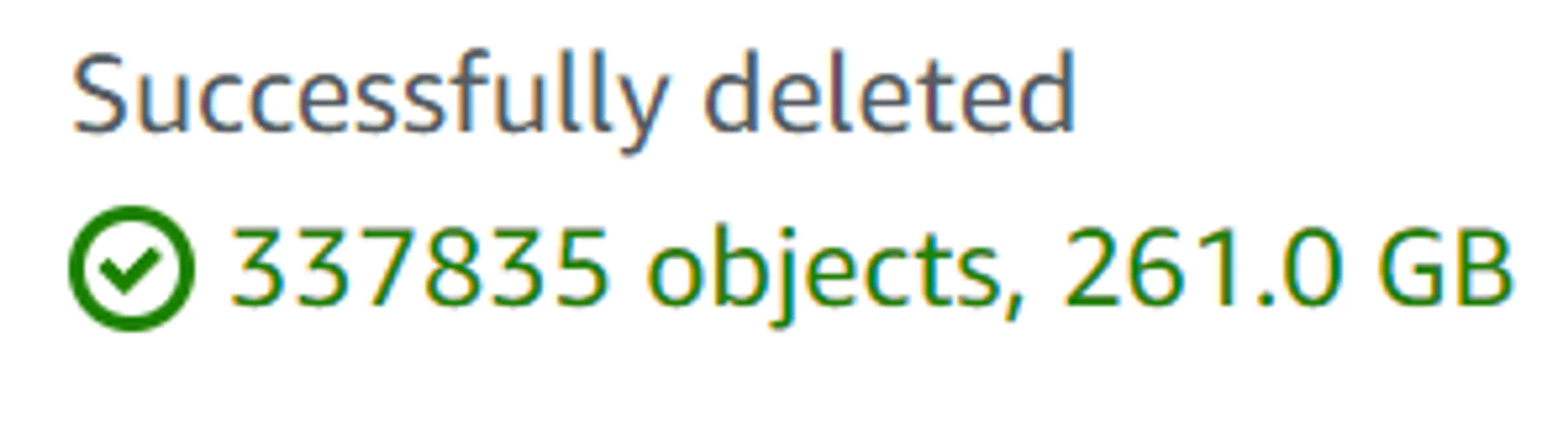
My new dist directory is ~100gb, compared to Gatsby’s ~260gb (some of this will also be because the full resolution JPGs are now compressed with MozJPEG) which will also save a bit of money in hosting costs.
Final thoughts
The product of all this work is, I believe, easier to use, significantly faster, and will be much easier to dev on.
I meant to measure the difference in payload size but I forgot. But what’s cool is how some pages require no JavaScript, or very little. The homepage for example contains no React components so it only sends 5kb of JavaScript. In contrast, every page on my Gatsby site shipped a JavaScript bundle which included React.
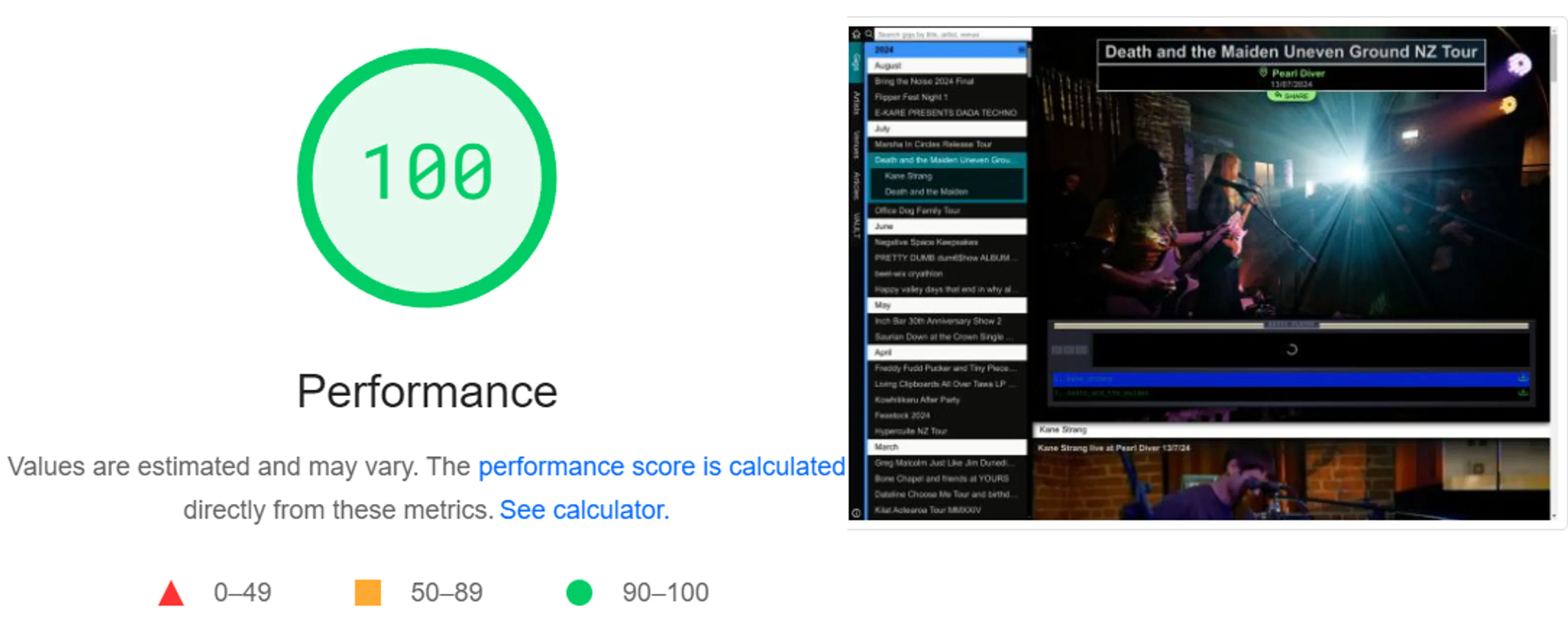
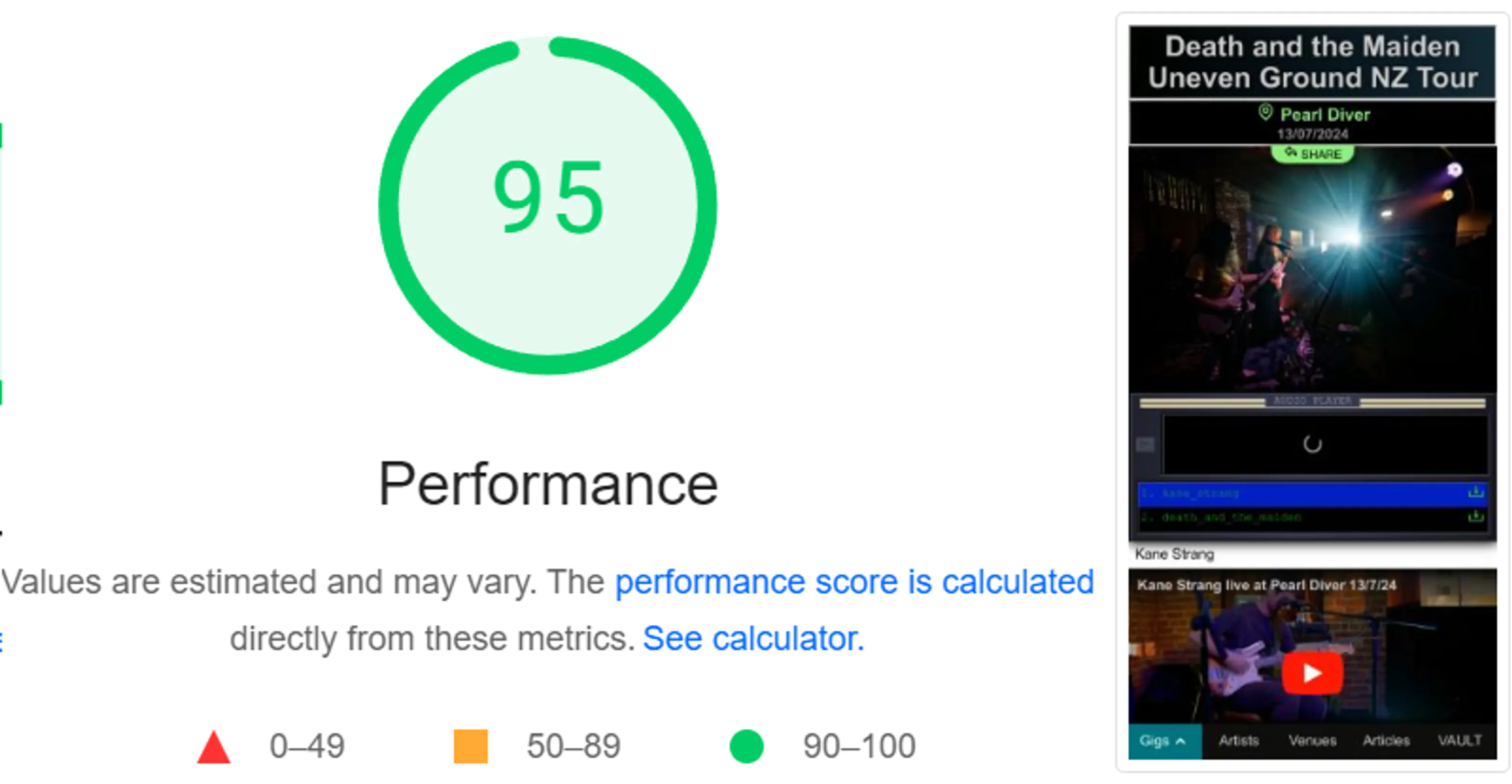
I also feel far more confident that this version of the site will remain maintainable for a longer term than Gatsby. I hopefully shouldn’t have to delve into Astro’s source code to solve niche problems.
Compared to Gatsby Astro is lower level, more flexible, and does less “magic” stuff for you. This suits me perfectly, it takes away a lot of guesswork, but it also means it gives you less out of the box and requires more code (although my total line count still ended up slightly less than the Gatsby version).
It feels like Astro maintainers are really trying to reduce dependencies and encourage the use of web standards rather than relying on something which inevitably stops being maintained. I can really see a future where Web Components takeover from frameworks.
Basically I really like Astro. It feels just thin enough to be useful instead of cumbersome, it doesn’t get in the way when it shouldn’t, and it provides a platform to use evolving web standards as opposed to some persons library which they will get bored of and stop maintaining in a few years. I just hope the “thinness” is a deliberate design decision rather than just because it’s new and immature. Only time will tell.
I also hope it doesn’t go the way of Gatsby and get eaten by worms.
As a sidenote, I’ve noticed “the internet is dead” growing recently as a sentiment and it bothers me.
I get why, there’s been progressively more rot introduced to the internet as it has matured, but it’s still a massively awesome place and that hasn’t really changed since its inception. There’s just more trash to sift through.
It can be whatever you want it to be. If it’s not catering to you then make something. You literally have the capacity to connect with billions of other people.
Bring back Y2K cyberutopian thinking imo.